
Hey everyone, Stratechery’s Ben Thompson gives a thoughtful take on AI regulation, Microsoft develops a prompt compression technique that improves LLM accuracy, and LLMs can learn from their mistakes.
Aside from that, several new tools were shared this week, which we’ll summarize at the end.
Misunderstood Innovation & AI Regulation
The biggest news this week in AI was President Biden’s executive order on Safe, Secure, and Trustworthy Artificial Intelligence. A couple days after the dust settled, Ben Thompson of Stratechery wrote a thoughtful article about regulation, showing how innovators and regulators cannot predict innovation by contrasting the mindsets of Bill Gates & Steve Jobs during the war over mobile.

Gates shows how even innovators get innovation wrong. He was so fixated on PCs as the computing hub, he failed to innovate the Windows Mobile interface. Jobs, on the other hand, was uncertain about the future, and that uncertainty led him and Apple to introduce a revolutionary multi-touch interface with the iPhone. The rest was history.
Ben extends Jobs’ and Apple’s success to AI regulation. He suggests that innovators and regulators should follow Jobs’ lead, embracing uncertainty and the unknown potential of technology, rather than preemptively stifling it with restrictive regulations, echoing Microsoft’s missteps. He warns that the government’s current approach risks inhibiting the an innovation that could benefit humanity, while also providing regulatory capture for the current AI front runners.
When Microsoft made the wrong call on mobile, only they lost out. The rest of the world still received an incredible amount of consumer surplus through iOS and Android (which changed their OS from resembling Blackberry to iOS after the iPhone release).
For regulation, however, the wrong prediction could prevent all of society from realizing the consumer surplus of an innovation that never happens.
I hope you read this article, and share your thoughts in the AI-Philosophy-Theory-Ethics channel.
Microsoft Tackles LLM ‘Lost in the Middle’ Phenomenon with Smart Compression Technique
A recent discovery shed light on the ‘Lost in the Middle’ phenomenon affecting Large Language Models (LLMs), where crucial information is overlooked when positioned within the middle of lengthy contexts.
Microsoft’s research team developed a a prompt compression strategy, termed “LongLLMLingua”. The method involves two steps:
- Coarse-grained reduction of the context based on document-level perplexity, followed by a fine-grained trimming using token perplexity.
- Fine-grained compression of the remaining text via token perplexity
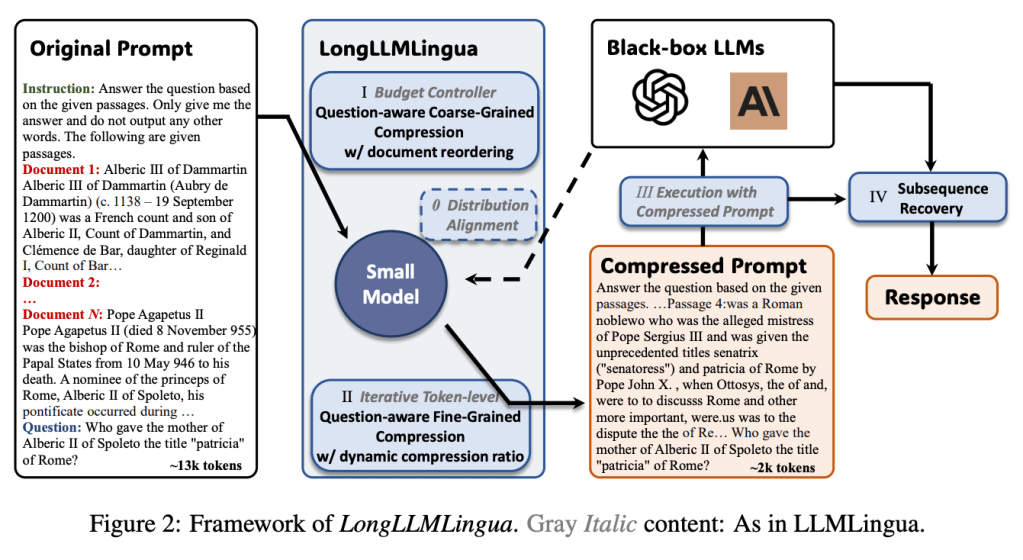
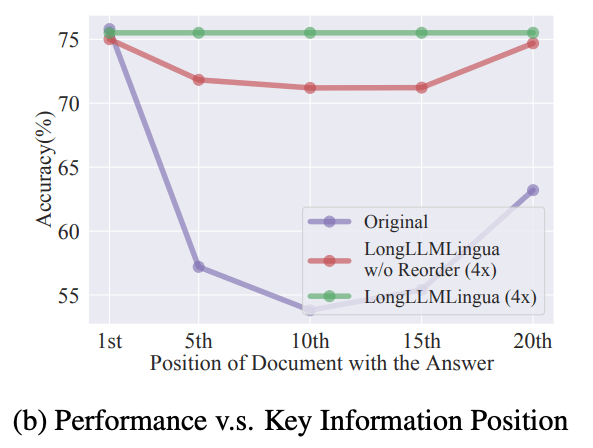
This approach enhances the model’s performance, and reorganizes the context by placing the most significant passages at the beginning and end, which leverages the positional bias to the model’s advantage. The result is a streamlined, efficient, and cost-effective process that transforms a potential weakness into a significant strength for LLMs.
LLMs Learn From Mistakes, Similar to Human Students
A new white paper, also with Microsoft participating, introduces “Learning from Mistakes” (LeMa), which teaches LLMs to solve math problems by learning from errors, similar to how humans learn by correcting their mistakes.
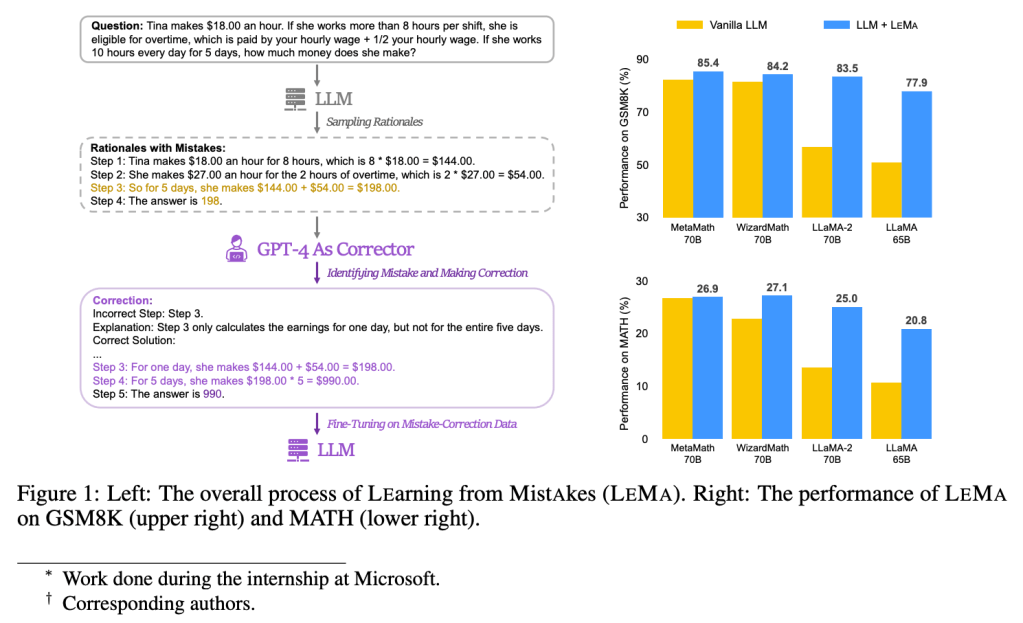
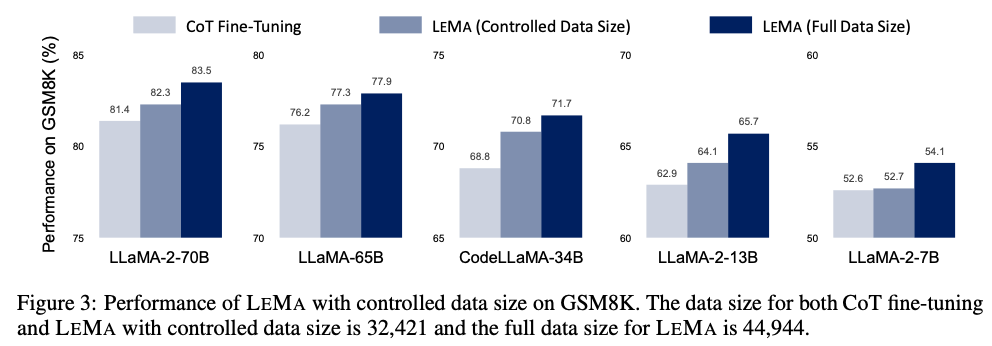
By replicating the error-driven learning process, LeMa fine-tunes LLMs on mistake-correction data pairs generated by GPT-4, significantly improving performance.
Their code, data, and models, are available on GitHub.
Member Tools & Resources
Several new tools were shared by members this week, so let’s sum them all up below.
AutoLLM
Special thanks to Akash, as well as Daniel, for sharing AutoLLM this week. Imagine a tool that combines the benefits of LangChain, LlamaIndex, & LiteLLM, and you can see the benefits of AutoLLM.
The image below sums it up well, and Akash elaborated more on a LinkedIn post.

Dust
Thank you Kyle for sharing Dust, this tool looks very compelling, especially for startups and smaller organizations.

Kyle summed up Dust on Slack earlier this week.
- Chat with GPT-4, GPT-3.5, and Bard simultaneously
- Multiple users in the same chat
- Create custom assistants to work with the other assistants
- Upload files for RAG
- All wrapped up in a nice interface that looks very similar to ChatGPT
OneAI
Thank you David for sharing this, OneAI is an NLP-as-a-service platform. Their APIs let developers analyze, process, and transform language input in their code. No training data or NLP/ML knowledge are required.
Their Language AI allows language processing with comprehension, of both meaning and information presented in text, generating structured data in context.
